A major task for any vendor is deciding how much to buy of each product when placing supplier orders to replenish stock. There are many strategies for this, but they all involve some manner of estimation of future sales quantities, whether implicitly or explicitly. The accuracy of these predictions can have a large financial impact, particularly for businesses dealing in perishable or seasonal goods. Even when surplus stock can be expected to be eventually sold, factors such as shipping costs and time, minimum orderable quantities, and inventory space all need to be taken into account while guaranteeing timely order fulfilment to customers.
Sales forecasting is a notoriously difficult task, both because of the inherent unpredictability of sales figures from period to period, and because of the sheer number of variables, most of which unknown, involved. Imagine trying to predict sales of beach balls for next summer: to make a truly informed prediction, you'd need to predict the weather, beach game trends, which colour of beach ball the celebrity of the week happens to be caught on camera with next month, and whether the pandemic will make yet another comeback - clearly, too daunting a task. The best we can do under any circumstances is to provide an estimated range of likely sales numbers given what little we do know at the time of prediction.
Although exact forecasting may be out of reach, we can do better than the very common method of simply replenishing stock by the same amount whenever it runs below a set quantity. To begin with, we can let this minimum stock quantity be selected per product by some clever statistical model, based on expected sales numbers during the time it takes for new stock to arrive. Moreover, the quantity to be ordered could be set in the same way if, for example, we would like to order once every two weeks from one supplier. If these estimates could be updated over time and allow us to specify the rough likelihood that stocks will last the full period, so much the better. Doing this manually for thousands or even just hundreds of unique products is tiring and time-consuming, to say the least, and likely to involve more than a small amount of guesswork. Even a small improvement, on the scale of a whole shop's worth of sales, can make a very big difference in time and money.
On that note, we are very pleased to introduce the Majako sales forecasting API, which makes forecasting sales extremely simple. It is fast, too - even with thousands of products and years of order data, the forecast is usually ready in the time it takes you to brew a cup of coffee (this is completely by design).
A forecast can be requested by submitting sales history in JSON or CSV format, specifying date, order quantity, discount rate (if applicable), and a unique product identifier such as SKU for each sale up to the current date. Furthermore, the length in days of the prediction period is required, and the consumer may optionally include a list of quantiles to be included for the predicted probability distribution.
The figure below shows a typical forecasting result for a single product: the API returns the predicted sales quantity and the requested quantiles, in this case at 10, 25, 75 and 90 %.
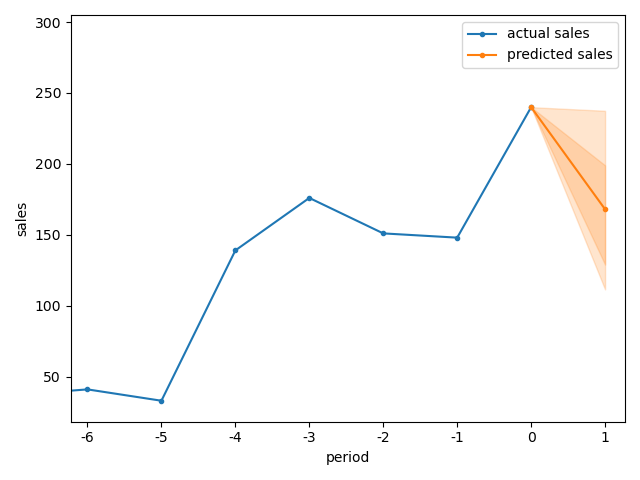
The quantiles represent uncertainty in the forecast: the outcome is predicted to fall within the darker shaded range with 50 % probability, and within the lighter area with 80 % probability.
For a better illustration, let us have a look at the plotted predictions for each month during the past year:
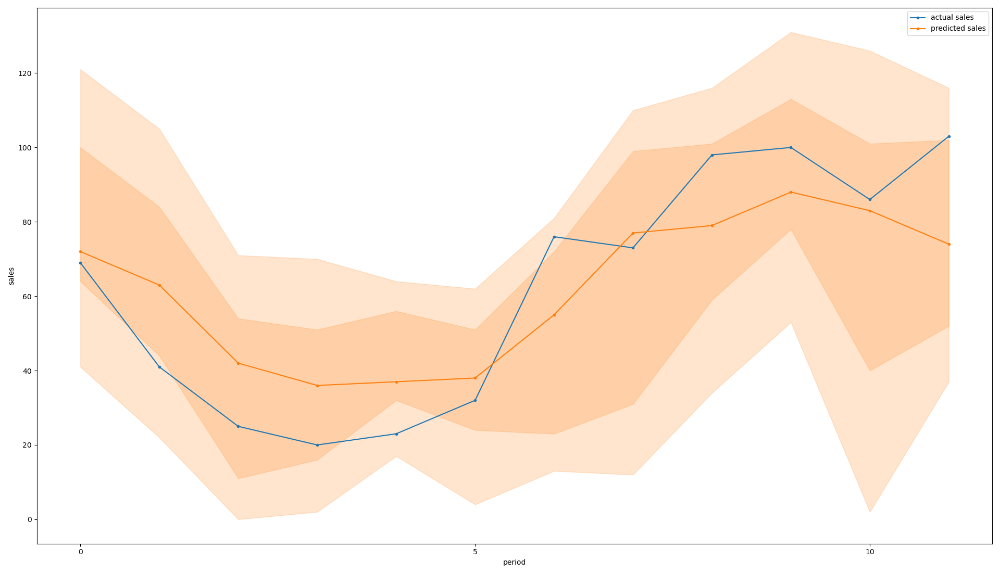
Each prediction point has been made with the actual sales data up to and including the previous month, just as in a real scenario. For the most part, the actual sales nicely follow the predicted trends and fall within the middle two quartiles. It is interesting to note that, although the model predicts a high probability of sales dropping as the high season ends, the actual sales bounce back up in the last period. In the following example, there is a sudden spike at period 10, after which demand drops more than expected:
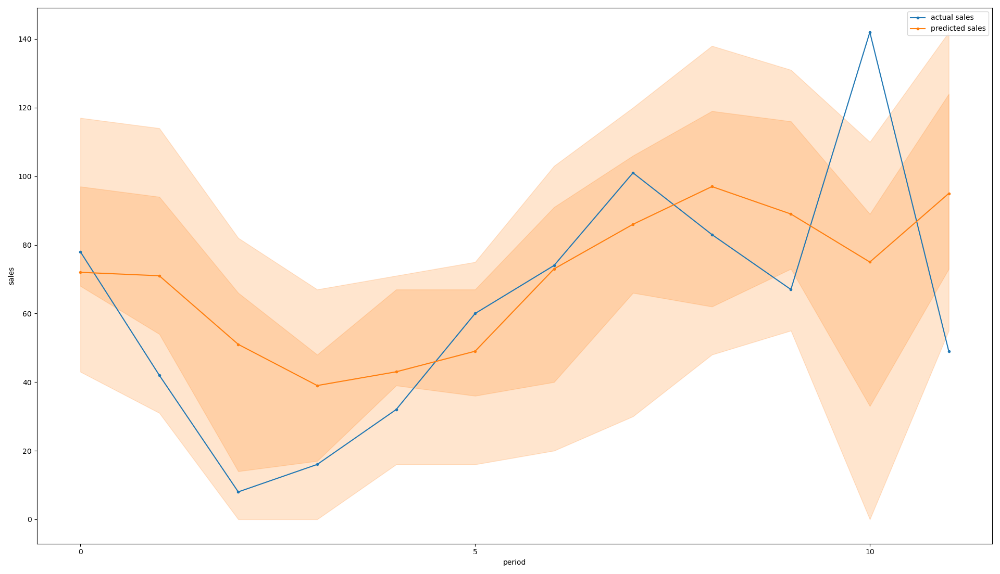
In both examples, sales were notably lower than predicted during the first 3-4 periods. This might be attributable to unusually hot weather during the time in question, as both products are seasonal items sensitive to weather changes (of which the model has no knowledge). The unexpected spike at the end of the second example is likely also due to a late final snowfall of the season, as the same spike can be observed for several similar products and there was no ongoing sale at the time.
The API consumer can use the predicted quantile values to make informed decisions on how much to order and keep in stock of each product: to guarantee (as far as possible) enough stock in 90 % of the cases, one should order according to the 90 % quantile.
The API response also contains some additional statistics for each product: mean and standard deviation of the prediction error. Both metrics are obtained by applying the trained model to the historical data and measuring how well it performs, weighted towards more recent sales. This information can be used to quantify how noisy and easily predicted each product's sales are. Another use is as a faster approximation of quantiles, if one assumes that the prediction errors follow a normal distribution.
Majako's sales forecasting model combines robust statistical methods with advanced machine learning. The model takes into account trends on multiple different time scales when extrapolating into the future, and learns to distinguish random noise from changing trends. Products are grouped according to how their sales curves behave in relation to variables such as time and discount, in a way that ensures maximum generalisation between similar products while keeping model sizes small.
The smaller - and simpler - the model, the lesser the risk of overfitting. An overfitted model will learn to overcompensate for small changes in order to reproduce outliers and rare events, and this can be rather dangerous as the model might predict a sales spike because it happened once in the past on an auspicious day when the stars were just right. Less certain events are instead captured by probability distributions given by the quantiles in the figures above.
The model's robustness can be seen in the following comparison with three common algorithms on the 100 best-selling products over twelve 30-day periods, in four real stores with completely different sales volumes and patterns:
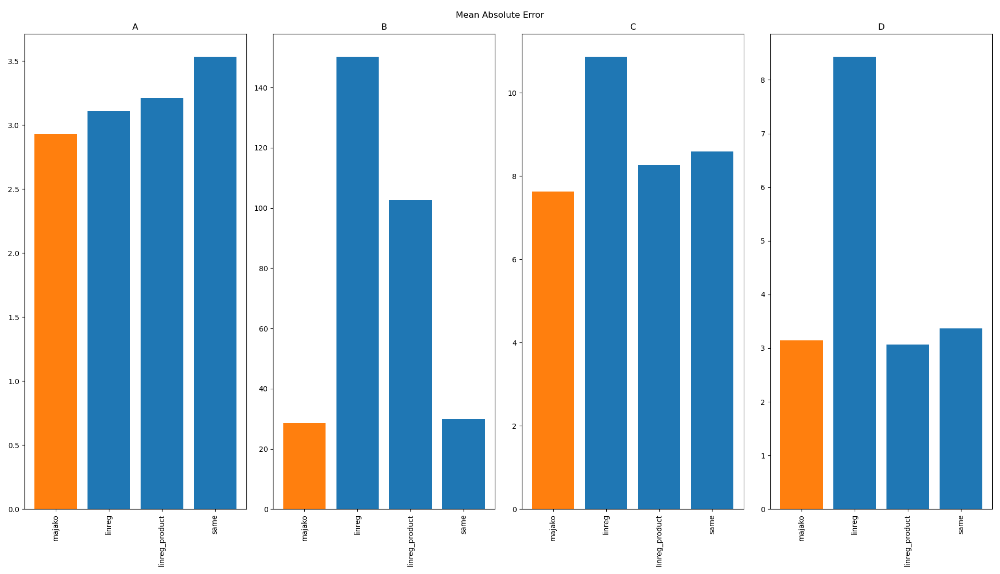
The height of the bars indicate the mean absolute prediction error, so lower is better. linreg refers to multivariate linear regression, using ridge regression predicting all products' sales at once. linreg_product also uses ridge regression, but with one model per individual product. same simply predicts each period as being the same as the one before - and as the chart shows, this is actually not a bad method, especially for noisy data, wherefore this is commonly used as a baseline comparison for more advanced models.
The differences are even more striking if we look instead at the mean squared error, which more strongly penalises outliers:
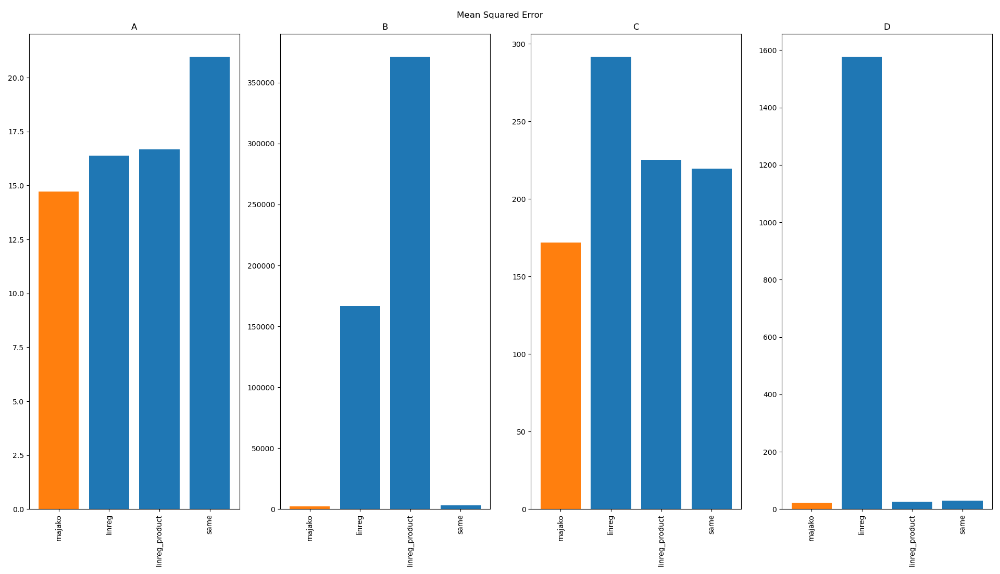
It can be seen that Majako's model gives consistently robust results compared to the other algorithms, and although it may be said that it tends to err on the side of caution when making the "hard" prediction, it is instead left to the API consumer to act on uncertainty by requesting the appropriate quantiles.
We have made the Sales Forecasting plugin for nopCommerce open source on GitHub to encourage others to make their own integrations with other platforms. The nopCommerce plugin itself can be downloaded from majako.net. Detailed API documentation can be found at docs.majako.net.
If your use case is more specific, or the API or model otherwise does not meet your requirements, do not hesitate to contact us at support@majako.se for a tailored solution!
Happy forecasting!
